Implementing Efficient Joins on Mobile App Data¶
No real world problem involving data begins with a single .csv file: much more common is the case of many files from various sources. When combining data from various sources, it often becomes neccesary to join our data properly. While languages such as SQL, or libraries such as pandas, have optimized ways to do this, one still may wonder the following important question:
What's happening "behind the scenes" when we join two tables with an SQL query, or two DataFrames with a pandas method?
In this notebook, we'll be studying the algorithms behind the joins. To do this, we'll use the data from two files:
- AppleStore.csv - a file containing data on apps from the Apple App Store
- googleplaystore.csv - a file containing data on apps from the Google Playstore
After carefully cleaning the datasets, we'll create a python Table() class which implements the following join algorithms:
- Nested Loop Join
- Hash Join
- Merge Join
to perform inner and left equi-joins. We'll then demonstrate our class on the above datasets, and use the performance to study the time and space complexity of each algorithm.
Summary¶
In the end, we found both theoretically and experimentally that:
- Nested Loop Join has time complexity O(N^2)
- Hash Join has time complexity O(N)
- Merge Join has time complexity O(N log N)
where N is the number of rows in each table (we assumed for simplicity that both tables have a similar number of rows). We conclude that the Hash join is the most efficient algorithm for our purposes. A figure demonstrating the time complexity of our implementation of each of the above algorithms is shown below.
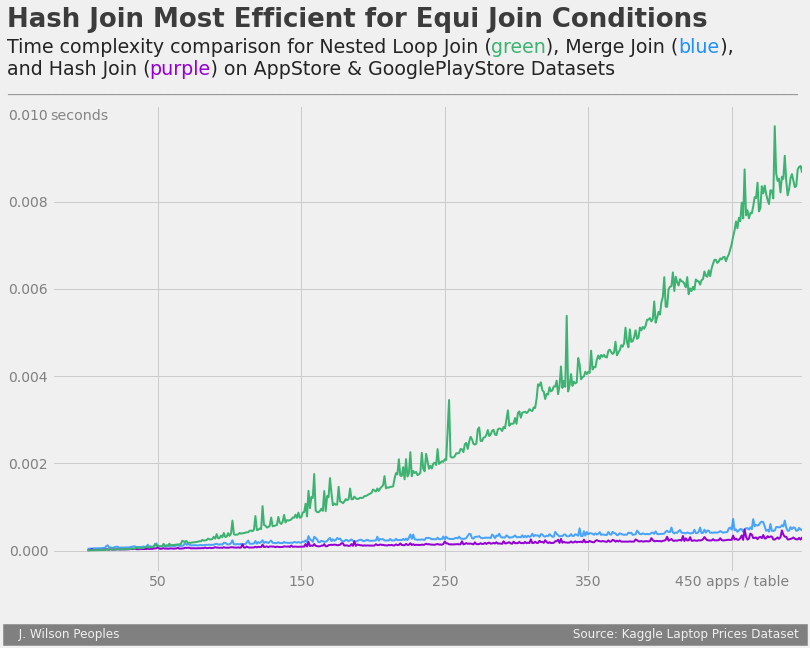
Its important to note that in this notebook, we only considered "equi join" conditions. For non-equi join conditions, the other algorithms show much more potential. To read more about non-equi joins, please see this link.
The final version of the Table() class, which we build throughout this notebook, is found below.
