Big Data Workflow: Augmenting pandas with SQLite¶
When we need to analyze data contained in a .csv file which is too big to fit into memory, what can we do? In a separate notebook, we investigated how chunk processing in pandas can be used to process the data. Some analysis, however, seems to require an entire column, or multiple columns, to be handled at once. One popular framework well equipped to work around such issues is MapReduce, which we discuss in a future notebook.
In this notebook, however, we'll use investment data from crunchbase to demonstrate how SQL can be used together with pandas to create a workflow that can deal with analyzing big data sets without putting too much pressure on our memory constraints. This workflow is best described in the diagram below.
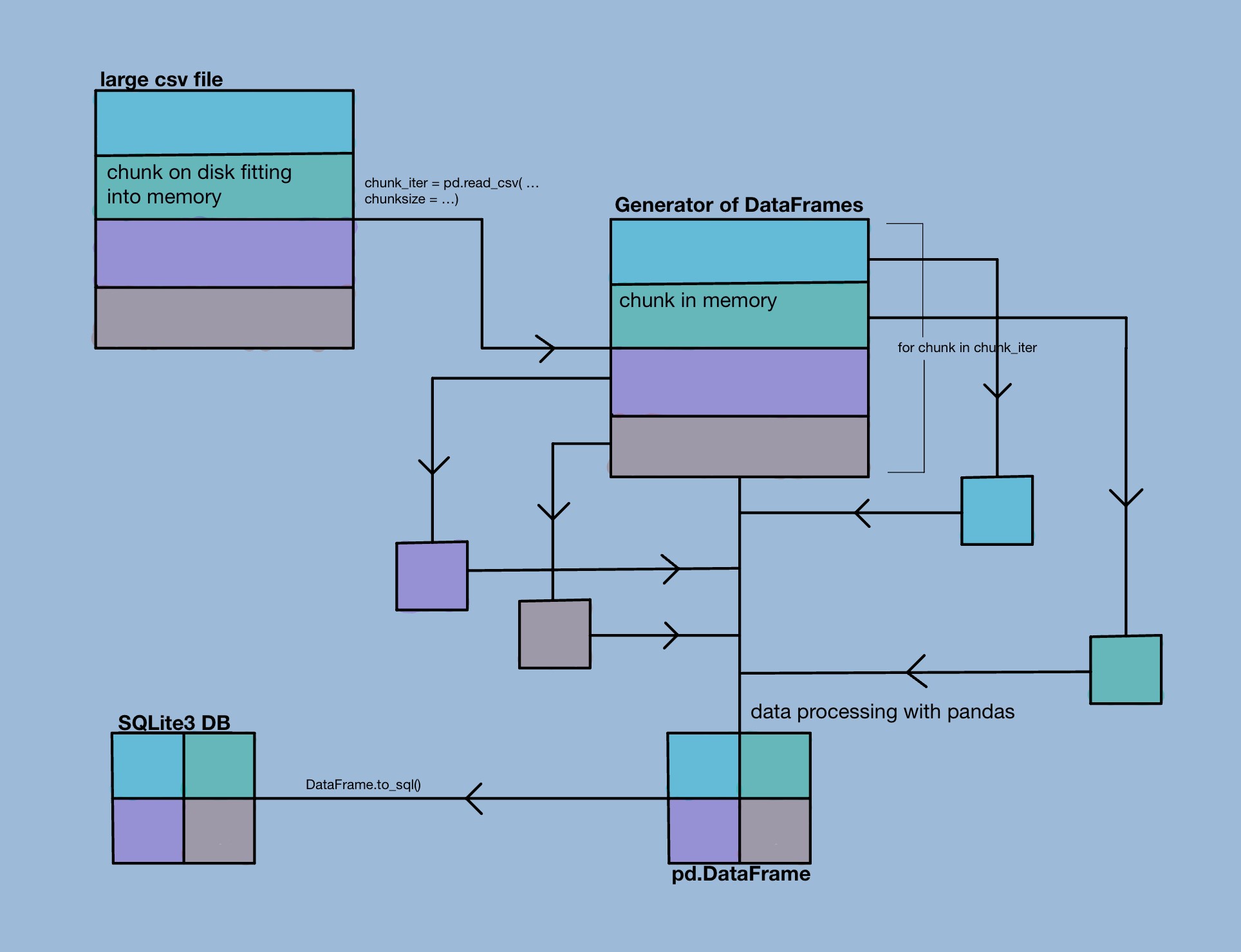
To simulate using a bigger dataset, we impose an arbitrary memory constraint of 10MB throughout the notebook.
Summary¶
In this notebook, we
- used chunk processing with pandas to decrease the total memory consumption of the data by over 30%
- converted the processed data into a database, chunk by chunk, using SQLtite3
- queried the resulting database to answer several business questions while remaining within the memory limit
Overall, we demonstrated a useful workflow for analyzing big datasets using pandas and sqlite3.
About the Data¶
The data analyzed in this notebook contains information regarding crunchbase fundraising rounds from October 2013, and can be found here. Since the purpose of this notebook is to demonstrate a useful workflow for analyzing large datasets, we don't include a data dictionary here. Column description information can be found in the above link.