Building a Crime Report Database with Postgres¶
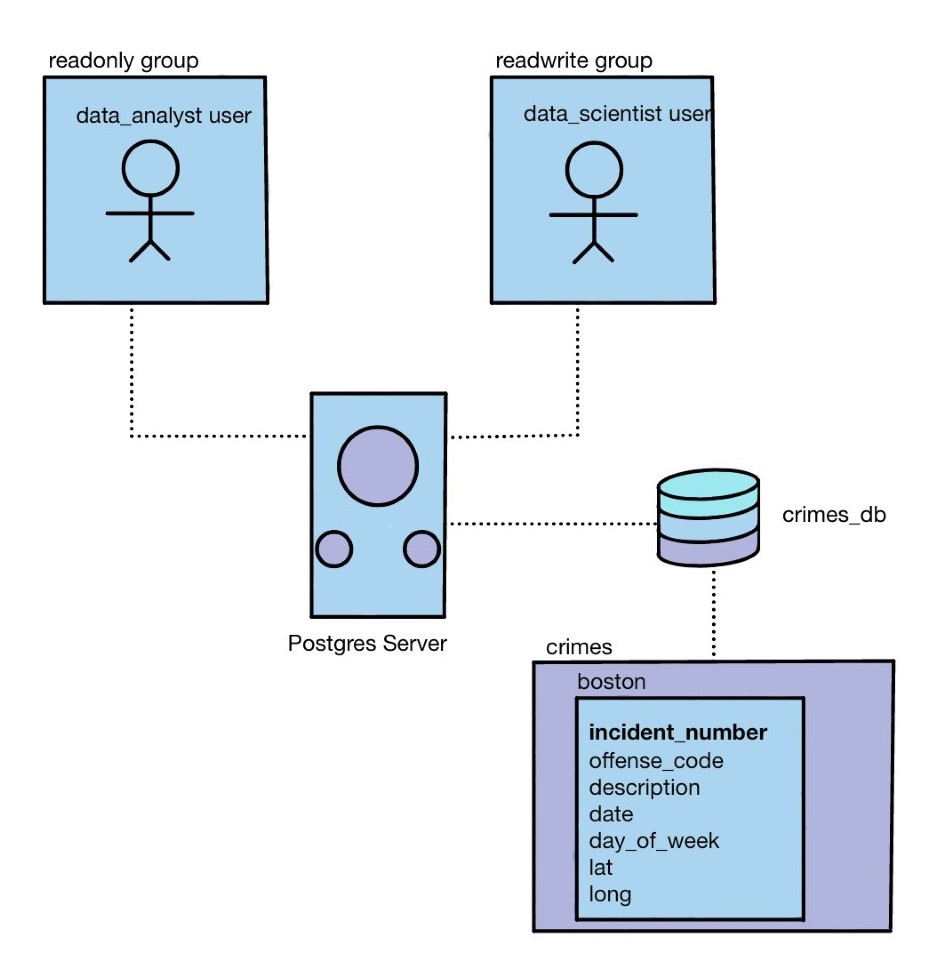
In this project, we'll be building a database for crime reports using Postgres. We'll begin with a csv file boston.csv, which contains information about crimes occuring in Boston. By the end, we'll have a database crimes_db hosted on a Postgres server, along with a table boston_crimes. We'll also create groups with certain priviledges, such as readonly and readwrite, corresponding to the typical data roles of data analyst and data scientist, respectively. A diagram showing the end product is shown below.